人工知能 に関連する言葉に中には、混同されやすいものがあります。その代表的な言葉が「機械学習」や「 ディープラーニング 」です。世のビジネスパーソンは、活用の幅がどんどん広がっていく人工知能について正しい知識を付けるための、これらの言葉の意味や違いを明確に理解しなければいけません。本稿では、そのうち機械学習について、できる限り専門用語を使わずに分かりやすく解説しています。

関連記事:
人工知能とは?具体的に何ができるのかを解説
関連記事:
人工知能の定義と分類についてわかりやすく解説

「機械学習」とは?ディープラーニングとの違い
機械学習は文字通り「機械的に学習すること」です。「コンピューターが機械的に?」なんて思われるかもしれませんが、要するに「繰り返し反復して学習すること」を指して機械学習といいます。
人工知能と呼ばれるコンピューターは、プログラムされた段階でこれといった性能を持ち合わせていません。では、どのようにして昨今活躍する人工知能が生まれているのかというと、開発者が無数のデータを取り込んで、学習を繰り返しているからです。その技術や作業を機械学習と呼びます。
一方、ディープラーニングは機械学習の一種ですが、その技術をさらに発展させたものを指します。詳しくは後述しますが、機械学習と異なり「より人間に近い思考回路で学習する」のがディープラーニングです。人間の神経回路を人工的に真似た「ニュートラルネットワーク」と呼ばれる回路を使い、高度な人工知能を作ります。
機械学習の分類
機械学習は大きく3つの学習方法に分類されます。それが、「教師あり学習」「教師なし学習」「強化学習」の3つです。学習方法によってどのような人工知能が生まれるかが異なり、開発者は適切な方法でコンピューターを学習させ、目的の人工知能を開発します。
教師あり学習
コンピューターに取り込むデータに「正解」となる情報を付け加え、それらの無数のデータを何度も学習する方法です。たとえば、「赤いリンゴ」の画像に「これは赤いリンゴです」というタグを付け加えた上で、コンピューターにデータを取り込みます。これを繰り返し学習することにより、次第にタグのない画像を見た時にも「これは赤いリンゴだ」と判別できるようになります。
教師なし学習
上記とは反対に、コンピューターに取り込むデータにタグを付け加えずに学習させる方法が教師なし学習です。「赤いリンゴ」の画像を例に挙げると、タグがないので新しい画像を見てもそれが「赤いリンゴだ」とは判断できません。しかし、データが持つ構造や特徴を分析し、グループ分けやデータの簡略化を可能にすることができます。
強化学習
「コンピューターが取る行動を強化する仕組みを強化学習」と呼びます。その際にポイントになるのが、特定の結果に対して報酬を与えることです。オセロのコンピュータープレイヤーで例えると、相手のコマを1つ裏返したら1点、2つ裏返したら2点、相手に勝利したら100点といったように、結果ごとに報酬を設けます。より高いスコアを出すことを目標として、繰り返しプレイさせることで次第に強度を上げていきます。
このように、機械学習の分類ごとに生まれる人工知能が異なり、開発者は目的に合わせた学習方法を選択したり、組み合わせたりすることで最終的な目標を達成します。
ちなみにディープラーニングは、教師あり学習を発展させた学習方法であり、それに強化学習を組み合わせたものを「深層強化学習」と呼びます。この学習方法の例としては、2017年に当時の囲碁トップ棋士を破ったグーグル社の人工知能が有名です。
機械学習のアルゴリズム
「アルゴリズム」というのは、コンピューターで計算を行う際の計算方式のことです。そして、コンピューターの世界にはさまざまアルゴリズムが存在し、目的によって適切なものが異なります。機械学習は効率よくデータを学習するために、それに適したアルゴリズムを使うのが一般的です。このアルゴリズムを大きく分類しますと、以下のように5つに分けられます。
1.分類(教師あり学習)
機械学習における基本のアルゴリズムが「分類」です。「画像を見て赤いリンゴを判断する」、「ECサイトにおいて購入・非購入を分ける」など、カテゴリーごとに情報を分類し、予測するための学習方法です。
2.回帰(教師あり学習)
上記同様に教師あり学習の一種であり、売上情報や事業成長率といった数量を扱う場合に有効なアルゴリズムです。たとえば、「過去の顧客情報から、最も購買に至りやすい顧客は誰か」といった情報を予測するのに役立ちます。
3.クラスタリング(教師なし学習)
「分類」の延長線上になるのがこの「クラスタリング」です。このアルゴリズムは、類似したデータの集まりを機能やカテゴリーごとに分けます。教師なし学習において代表的なアルゴリズムであり、過去の情報から未来の情報を予測するのに役立ちます。
4.次元削減(教師なし学習)
機械学習において、情報の特徴量が多すぎると分析精度が悪くなることがあります。次元削減とは、情報の次元(特徴量の数)を減らすことで、情報量の圧縮や正しい情報可視化を促すためのアルゴリズムです。
5.異常検知
機械やシステムの故障・障害などを、情報分析を用いて検知・推測するのが異常検知です。あらかじめ規定された閾(しきい)値によって異常を検知する場合と、閾値が設定されていなくても異常検知する場合があります。
この他にも、機械学習のアルゴリズムはたくさん存在しています。機械学習にどのアルゴリズムを取り入れるかは、マイクロソフトのチートシートなどを参照にするとよいでしょう。ちなみにチートシートとは、ごく短時間で目的とする機能やコーディングを見つけるための資料です。
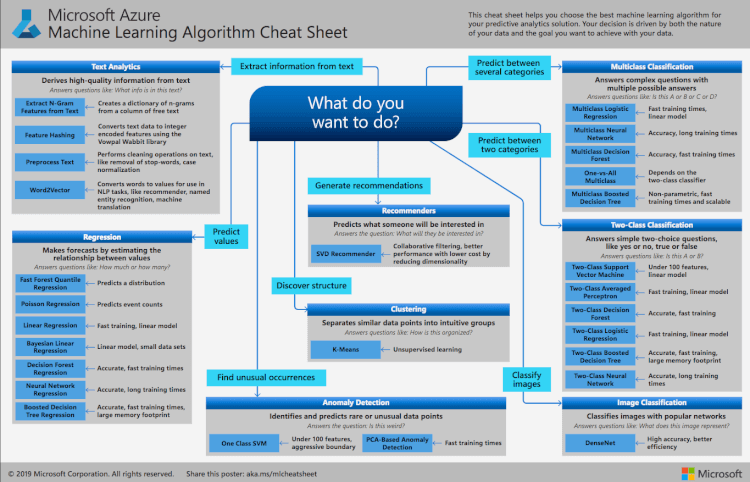
Microsoft Azureとは何か?入門から応用まで徹底解説


機械学習を使って人工知能を開発する
人工知能と聞くと高度な技術によって開発されるものを考えられがちですが、一般的な機械学習を用いる人工知能ならば、特段高い技術が無くても開発できるのが現在の人工知能業界です。
特に、Microsoft Azure などにおいてクラウドサービスとして提供されている人工知能および機械学習は、既存のシステムや新しいシステムへの組み込みも容易であり、人工知能を活用したビジネスを誰もが展開できる環境が整えられています。人工知能を活用することで、労働者不足問題の解消、経営情報可視化や予測、労働生産性向上、リスクマネジメントなど、非常に広範囲な効果が期待できます。さらに、機械学習を使って顧客満足度を向上させたり、新しいビジネスを創出したりすることも可能です。今や機械学習を用いた人工知能を開発するために必要なのは、目的に応じたデータだけです。人工知能を開発するためのサービスを検討し、この機会に人工知能をビジネスに取り入れてみてはいかがでしょうか?
関連記事:
Azure Machine Learningによる人工知能の実践的活用
関連記事:
AzureのAIプラットフォーム、その可能性とは























